Interacting With Health Data Like Its 2026
When I first started this blog I was inspired by the Apple Health Lake concept of taking your health data and applying a data lake to it in order for it to be queried. It was always possible to download your data from Apple as an .xml file but for ongoing insights the original intent was to use a dashboard as was the trend of the time.
What I ended up initially with was a derivative copycat although I justified its value to me at the time because for every individual their own health data matters for them. However I feel like I have moved on from that paradigm so I want to update my blog to discuss the ideas behind why changes have been made. Earlier I wrote about using LangGraph as a fitness agent but I have come to the conclusion that I have no domain expertise on generating structured training workouts based on my goals and biometrics so I would rather have the agent decide for me.
The original person behind the idea of the Apple Health Lake wrote during a time before large language models were introduced to the general public. By aping his project I indirectly followed his goals such as replicating a dashboard. Whereas before dashboards were how users interacted with data and the eventual output that was being built toward I believe agents leveraging text to SQL will replace that. After making several dashboards professionally and personally I have come to the conclusion dashboards are like lava lamps in that they grab visual interest initially but they eventually lose your attention and are liabilities that need maintenance. A fitness agent on the other hand does not fall in to the same trap and might get better the longer the interaction continues. Another thing the person behind the original health lake concept was operating under was the data lake. At the time this was still cutting edge and the best way to get a cheap solution for a home project compared to enterprise pricing for a cloud data warehouse. A concept at that time that was gaining popularity was the lakehouse and it is the second thing I will discuss in more detail in this blog post. The problem or opportunity then is figuring out how to make the transition into lakehouse architecture.
Data Lakehouses Solve For Idempotency
With my fitness agent I want to be able to transmit data not only about what I have done in terms of workouts in the last few days up to yesterday but how I am feeling this morning and how my sleep went the previous day. A scheduled daily ingestion is not the right pattern because if I want the workout first thing in the morning the data for that morning will only arrive by the next day. If my pipeline is not idempotent if I send data relating to the same day in more than one API request (for example a preliminary amount of data in a post request after getting ready in the morning and another post request the data for the same day after it has concluded) I will end up with duplicated data at query time. A lakehouse is the way to solve this problem because instead of file based append like with OLAP ingest only pipelines you can design row based transactional upserts more similar to OLTP pipelines.
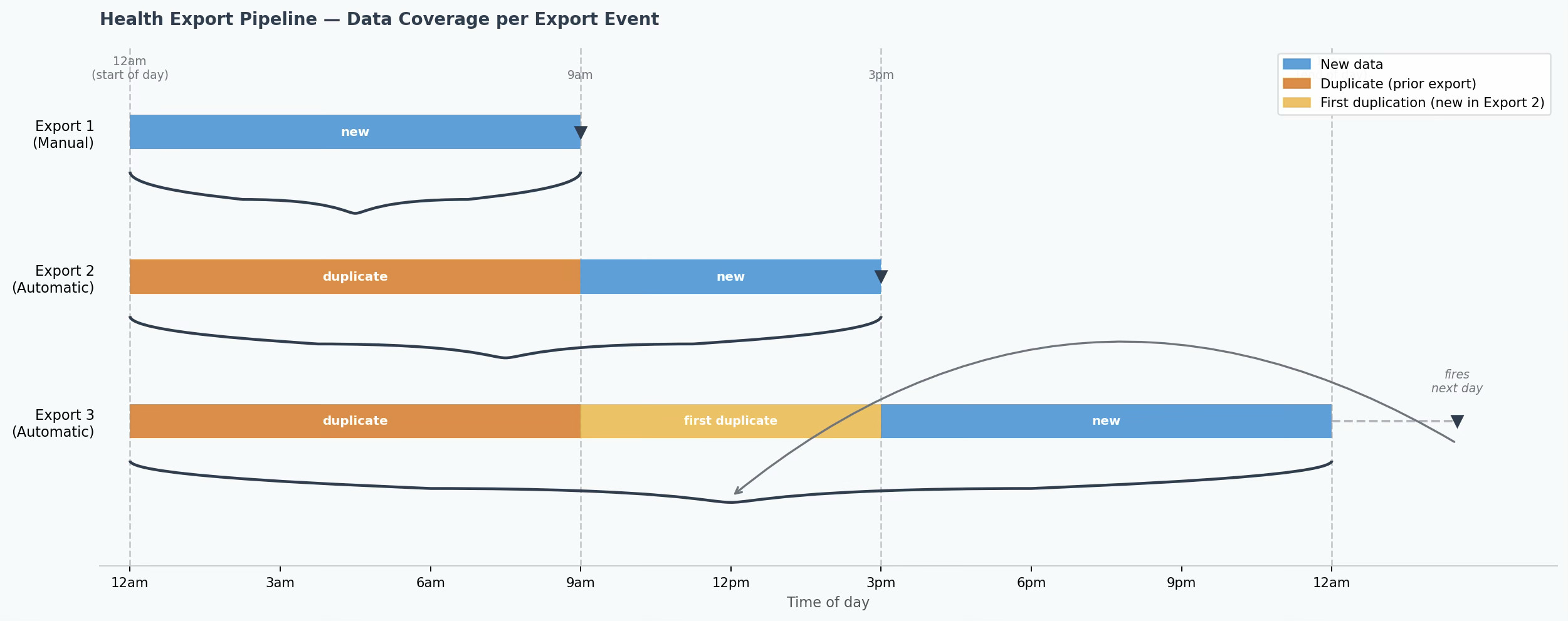 Agent Engineering Requires Sophisticated Idempotency
Agent Engineering Requires Sophisticated Idempotency
That means even if data later in the day for some reason has less data or no data that will not automatically overwrite what exists already to be queried.
When I was researching how data lakes and data warehouses worked the concept of schema on read and schema on write was just technical jargon that went over my head. However after dealing with schema on read systems for a while with my data lake I think I will never go back to that system because I think it is inferior. Particularly the problem is that with schema on read if there is unanticipated schema change for example if your data is floating point integers and suddenly you get new data with only rounded whole integers that schema mismatch will corrupt the whole table. It is absurd to me that data arriving later in the pipeline can lock you out of making queries relating to data arriving earlier in the pipeline that previously worked just fine. That is why in those cases I would rather that schema on write is enforced and new data fails to write. I do not know what the future of data lakes holds but I am bearish on the concept. They work well for append only IoT pipelines with stable API requests and where query or interaction primarily happens through dashboards. However dashboards themselves seem to be going away in enterprise environments. Most relational business data have long moved on to lakehouses so changes have already been brewing.
Another aspect behind why data lakehouses are the superior format in my case is that managing glue partitions manually with lambda code is an enormous amount of ELT work for no benefit in event driven architecture. There is schema to manage on both raw and curated data and dealing with empty payloads, duplicate payloads, corrupt payloads are all contingencies that you have to design around in order to obtain a fault tolerant data solution. I did all of this before using large language models like Claude Code in my workflow which would have made it easier but it is inconvenient. With schema on write I was able to avoid that hassle by relying on simple to understand MERGE INTO syntax.
Having access to time travel is a weight off my shoulders. Rolling back something which breaks the pipeline is good to have in the back of your mind. In my testing things like schema changes, bad data quality, bad ELT code can all bring your pipeline to a standstill and that is something I do not want to have to deal with.
Last thing to mention is the idea of upserting data in order to get around the problem of API requests being restricted to 10MB max file sizes. One of the solutions I had in mind before deciding against is replacing API Gateway with just a server that can take uploads of any size. That seems to me like a waste of a server although in the future when I possibly migrate to a local solution because this is sensitive data that might come into play a bit more.
If my fitness workouts over the course of a day exceed 10MB which they do then lakehouse is a better solution for SCD Type 1 data pipeline. This is because object storage is immutable whereas tables can relatively easily handle table upserts. The problem is that data written into by the second is quite large and requires some degree of big data engineering. In my earlier testing I had some regrettable workarounds that sidestepped this problem. One of those poor solutions was to temporarily query the data from Garmin because I record workouts on both my Apple Watch and Garmin at the same time whether that is running or cycling. Another thing I did was choosing in the Health Auto Export app to configure the post request so that data was by the minute rather than by the second. This makes the data 60 times smaller as a first approximation which makes the problem go away but ignores that this loses a lot of useful information. The solution instead is to employ a strategy called data chunking. The app restricts me here because I can only chunk on route and health metrics. In my testing this implementation is still has limitations. If, for example my workouts are longer than 6 hours then the subsequent payloads can be rejected by API gateway for exceeding 10MB. This is rare and possibly might only come into play if cycling for the entire day but it is a drawback nonetheless.
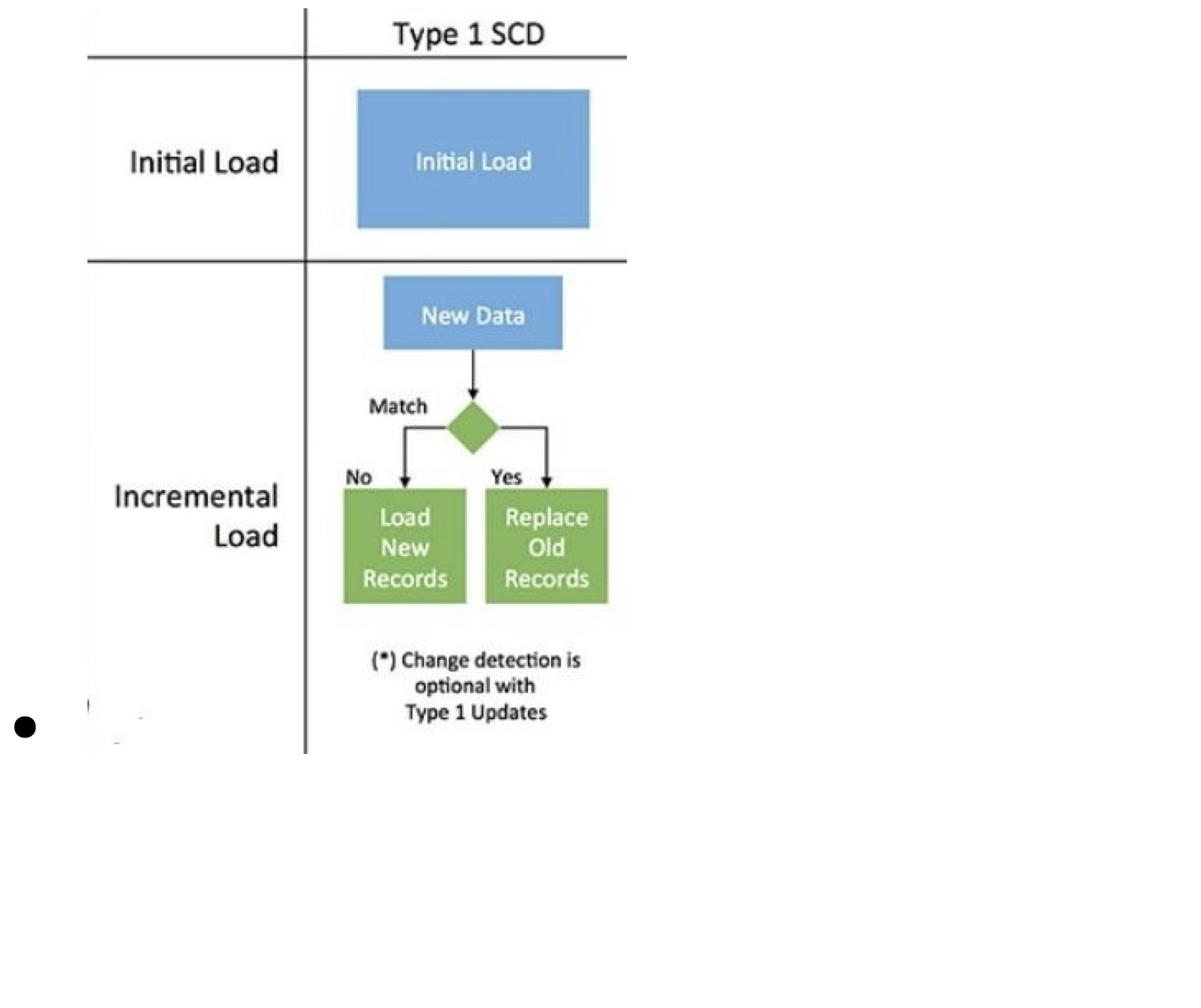 Type 1 SCD (Slowly Changing Dimension)
Type 1 SCD (Slowly Changing Dimension)
DuckLake Is A Great Solution For Medium Sized Data
The lakehouse has existed since 2020 so excluding the agentic workflow the pipeline could have been designed this way five or more years ago so what was stopping me? A roadblock that prevented me from jumping on board with this type of solution was that lakehouses are hard to understand (data lakes and data warehouses are hard enough abstractions to get your head around by themselves let along combining them), hard to implement (sometimes requiring knowledge of JavaScript or Spark), and hard to monitor (each write generates a bunch of files sometimes in .avro format). A breakthrough for me came with the introduction of DuckLake from Motherduck in 2025. I am writing this in 2026. I appreciated the work MotherDuck did making OLAP databases easier to understand and use with DuckDB and that goodwill encouraged me to struggle through the DuckLake learning curve. Understanding that there are three legs on a stool made sense. The syntax is easier and the number of files generated makes it less overwhelming. It is interoperable and low cost. I think it is the perfect solution for every home data project you can imagine. In my case I am dealing with tens of millions of rows of data, too big for a spreadsheet but overkill to use a data cluster hence this would be medium sized data.
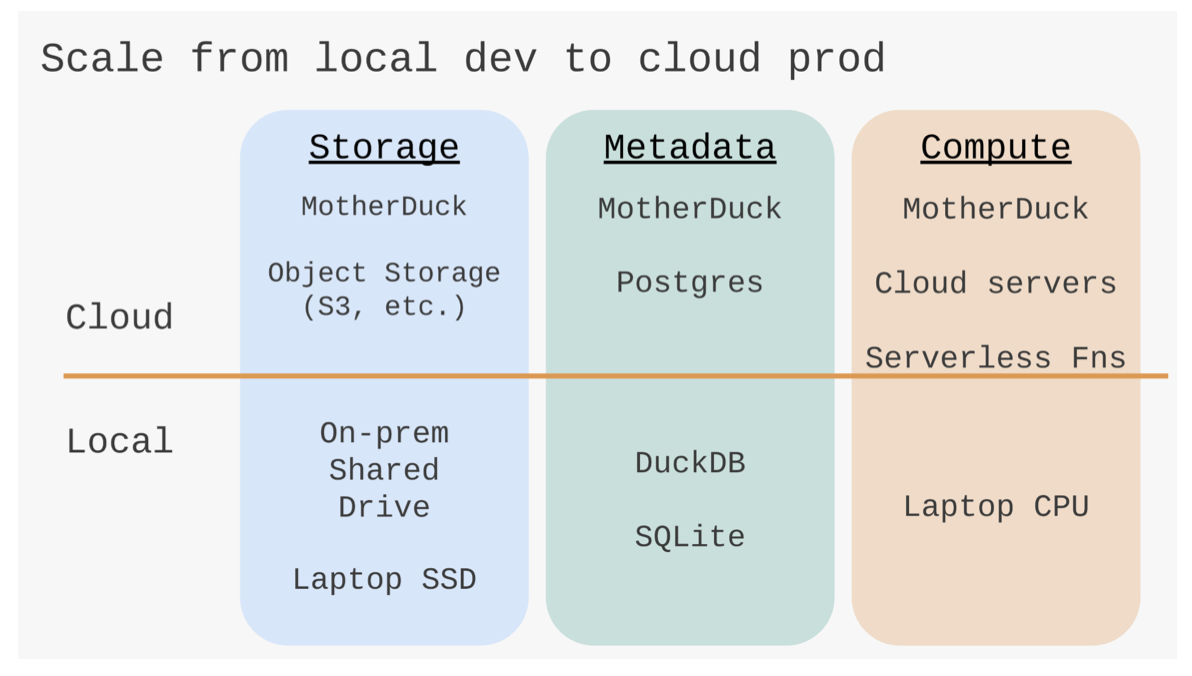 Going From Cloud To Local For Sensitive Data Is Easy
Going From Cloud To Local For Sensitive Data Is Easy
Although “Bring Your Own Bucket” implementations of DuckLake are offered and encouraged I could not find any reference to others who had implemented one at the time of writing. I am happy to declare that I implemented one in this style with no issue.
Fitness Agents Are Capable Provided You Design The Right Harness
I am happy to delegate the decision making process of what my next workout should be to the large language model in a harness because they are very good at being knowledgeable in terms of training data and resourceful from having encyclopedic knowledge of everything. Therefore my job is just to give the agent my data along with my preferences, engineer it smoothly and let it be a black box that I mostly do not question.
I have simplified my LangGraph DAG from before by routing any query relating to data in the lakehouse to a single deep agent node. The other path is a tool call that allows the agent to access my training calendar in order to upload workouts via an API.
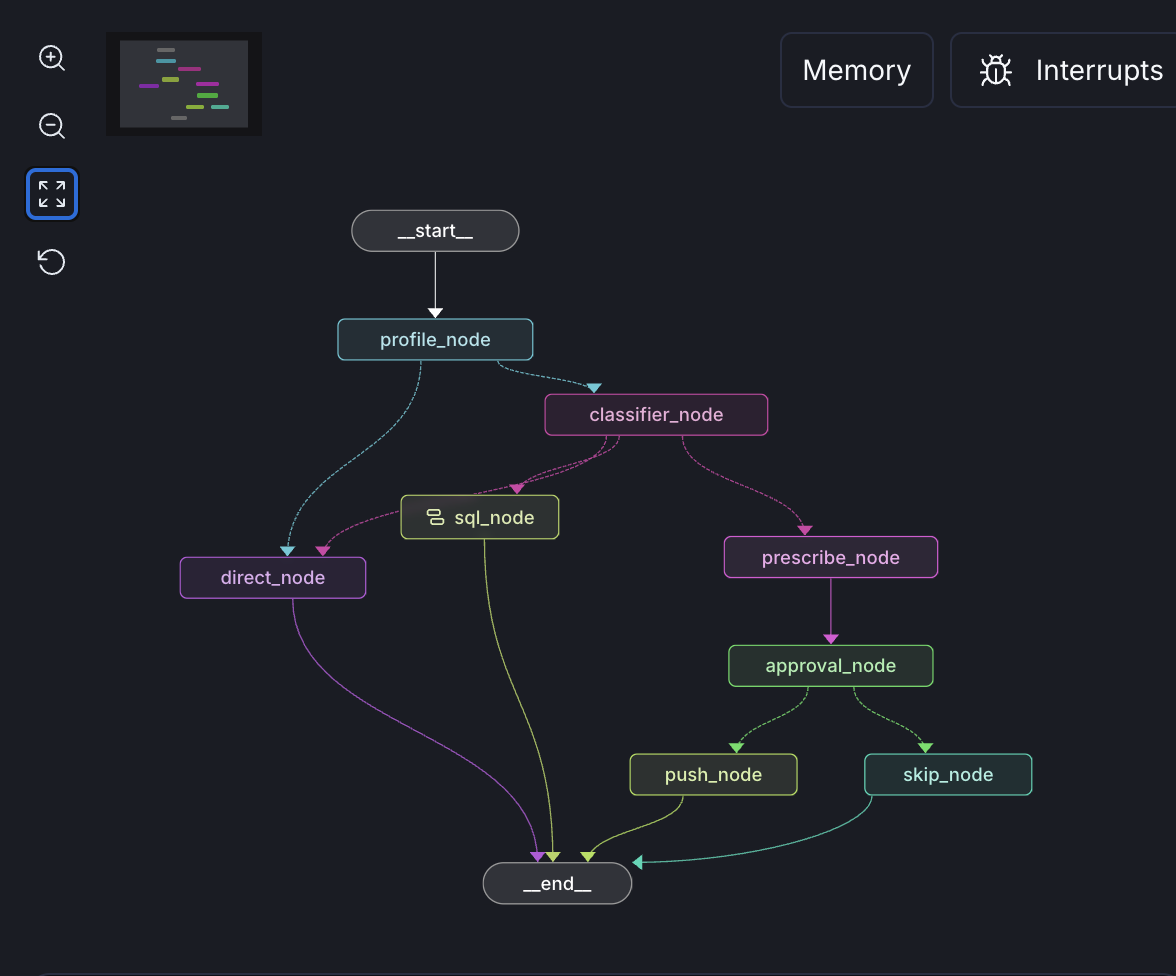 New LangGraph Agent With Less Path Redundancy
New LangGraph Agent With Less Path Redundancy
The Solution Diagram
A lakehouse simplifies my solution diagram because there is much less event driven file management compared with a data lake medallion architecture.
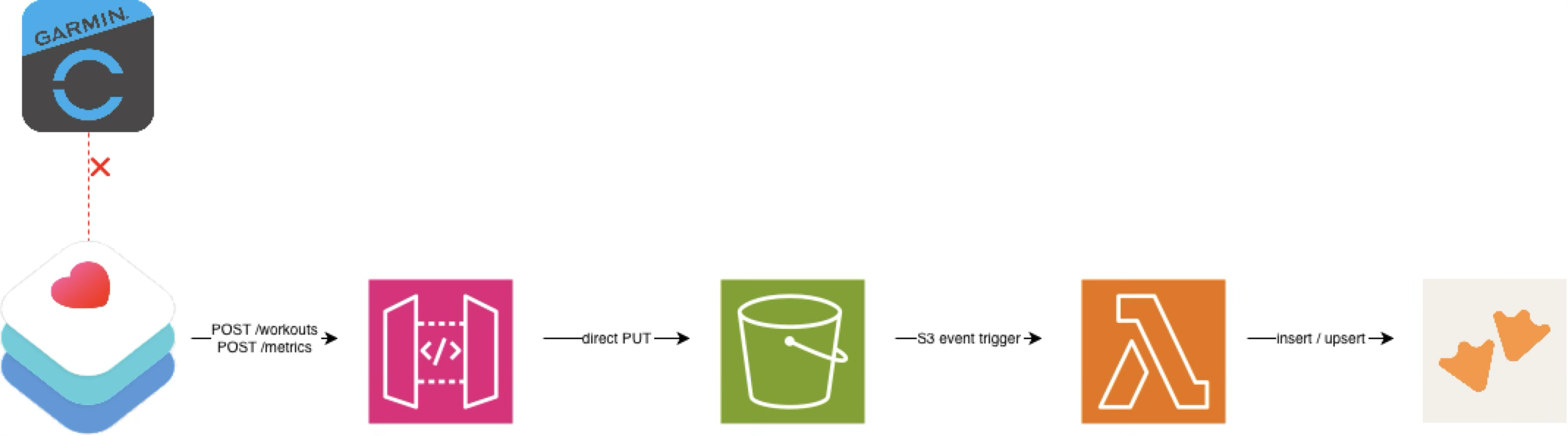 A Sleeker Cloud Diagram
A Sleeker Cloud Diagram
The Semantic Layer
A semantic layer is no longer optional when it comes to data pipelines. Eventually most analysis of data may be driven by agents who can write perfect SQL just like they can write perfect regex. Therefore expect the semantic layer to go from niche jargon to a requirement going forward. However although LangGraph text to SQL agents are quite capable they are not anywhere near comparable to analysts when it comes to writing complex SQL queries. During the planning phase they can get overwhelmed or sidetracked by the difficulty of the problem. This is because they are locked into the harness and they are inherently language models.
What Else Exists Or Will Exist
At Apple WWDC I was watching the presentation this year expecting them to release or foreshadow something related to structured training with biometrics but first party. I was convinced of this since this was their big AI conference that analysts had been hyping up for months but was disappointed with what was shown at least for Apple Healthkit. Despite being early adopters in the field of health tracking and fitness wearables Apple has been lethargic in entering into fitness agents which seems odd to me given how well positioned they are in terms of the amount of data they have.
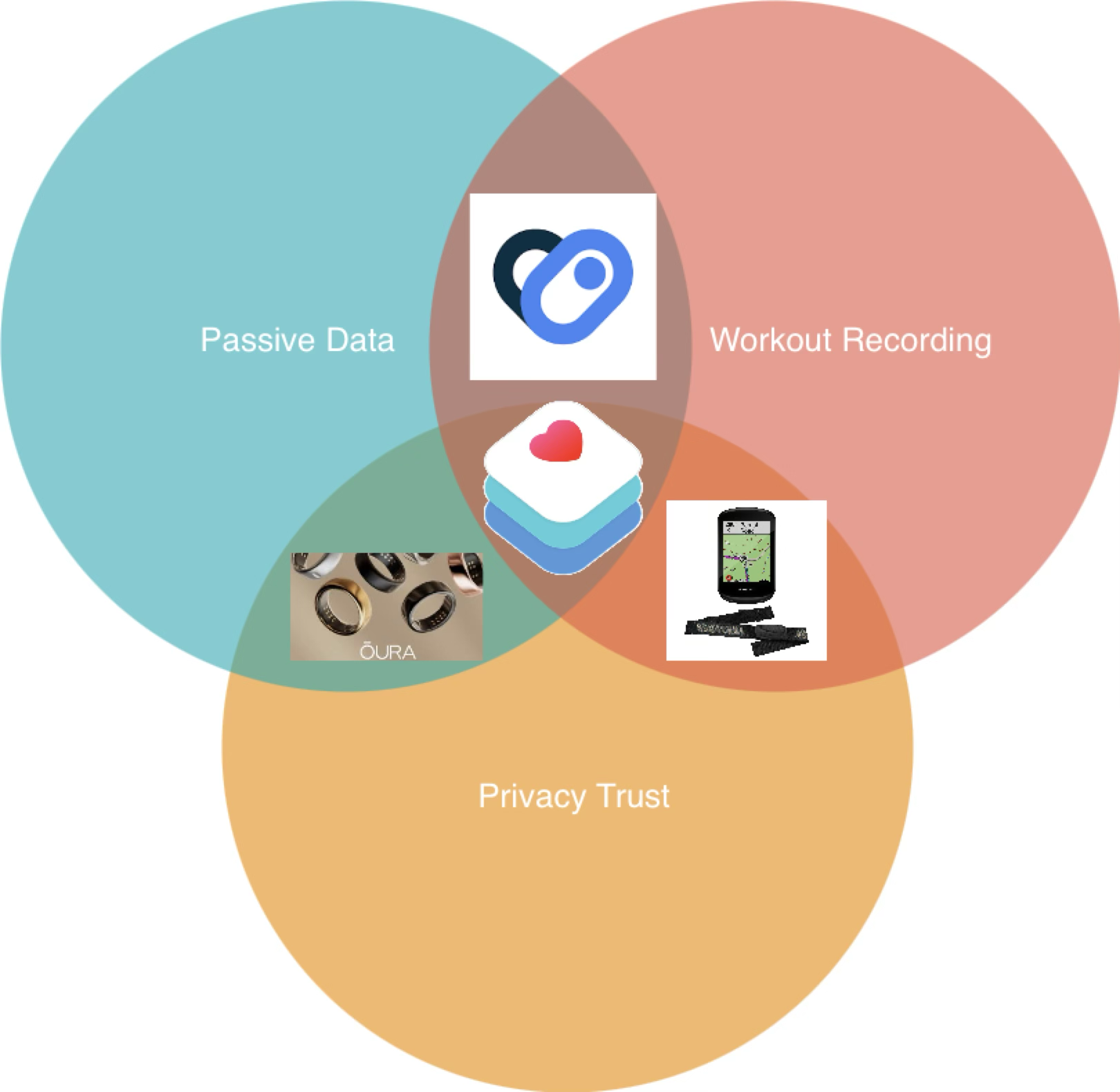 Apple Is The Market Leader For Big Health Data
Apple Is The Market Leader For Big Health Data
I feel as though in coming up with this project and executing it I have been racing against two groups. The first group is Apple themselves because they have all the ingredients to create something like this but better and first party. The other group I am racing is the community of data and fitness and quantified self enthusiasts engineering similar projects with agents and health data. What I have noticed is that everybody comes at this topic from a different angle with different goals, different implementations and different wearable health hardware. My stack of health hardware includes a Garmin watch and an Apple Watch. Somebody with a whoop strap might execute something similar to this but different because they don’t have what I have or may not want the hardware I have. Someone else may execute a micro SAAS because they have entrepreneurial ambition, someone else might think agents are pointless and think dashboards are the way forward. Regardless I will stake out the position that this array of products and execution is valuable because it ticks a number of boxes at once.
Demonstration
A companion video to go with this blog post explaining why things are how they are is provided below.
While In My Earlier Presentation The Ideas Were All There The Execution Was Lacking